Оверфиттинг: самая важная научная проблема, о которой вы никогда не слышали
Оверфиттинг: самая важная научная проблема, о которой вы никогда не слышали
Когда статистики ошибаются и принимают шумы за сигнал, они называют это оверфиттингом[78]. Представьте себе, что вы – мелкий уголовник, а я – ваш босс. Я поручаю вам найти хороший метод подбора цифровых комбинаций для цифровых замков, аналогичных тем, что можно найти в школьных шкафчиках (возможно, мы хотим стащить у школьников деньги, припасенные на обед). Я хочу, чтобы вы нашли способ, позволяющий с высокой вероятностью подобрать нужную комбинацию замков в любое время и в любом месте. Для практики я даю вам три замка – красный, черный и синий.
Поэкспериментировав с замками в течение нескольких дней, вы возвращаетесь ко мне и рассказываете, что смогли найти ошибкоустойчивое решение. По вашим словам, если замок красный, то правильная комбинация – 27–12–31. Если он черный, то нужно использовать цифры 44–14–19, а если синий – 10–3–32.
На все это я могу сказать только то, что вы не справились с заданием. Очевидно, что вы вычислили, как открыть эти три конкретных замка. Однако вы ничего не сделали для создания теории, позволяющей открывать замки, когда комбинация неизвестна нам заранее. Допустим, я бы хотел узнать, можно ли открывать эти замки с помощью скрепки из хорошей стали или же следует воспользоваться каким-то присущим им механическим дефектом. Даже если бы это вам не удалось, вы могли бы найти какой-то обходной маневр – например, какие-то цифры, которые появляются в комбинациях чаще других. Вы же дали мне слишком конкретное решение для общей проблемы. Это и есть оверфиттинг, и он способен привести к ухудшению любых прогнозов.
Название оверфиттинг (оverfitting) связано с тем, что статистические модели «подстраиваются, подгоняются» (fit) под прошлые наблюдения. Степень подгонки может быть слишком общей. И такое явление называется «андерфиттингом» (underfitting). При андерфиттинге вы захватываете меньшую часть сигнала по сравнению с максимально возможной. Либо же модель может обладать свойством оверфиттинга, иными словами, ваши данные содержат слишком много шума, что не позволяет четко выявить структуру, лежащую в их основе. На практике второй тип ошибки встречается намного чаще.
Чтобы понять, как это работает, давайте использовать допущение, которого в реальной жизни не бывает почти никогда. Мы будем точно знать, как должны выглядеть реальные данные. На графике на рис. 5.4 изображена гладкая параболическая кривая с максимумом посередине. Такой кривой можно описывать любые интересные для нас данные из реального мира. Например, как мы уже видели в главе 3, именно такая кривая довольно четко описывает изменение результативности бейсболистов с увеличением возраста, поскольку они значительно более результативны в середине своей карьеры, чем в конце или начале.

Рис. 5.4. Истинное распределение данных
Однако мы не можем наблюдать эту зависимость напрямую. Вместо этого мы имеем набор отдельных точек, характеризующих данные, на базе которых мы должны найти закономерность. Кроме этого, на эти точки данных влияет масса своеобразных обстоятельств – иными словами, у нас имеются и сигнал, и некоторый шум.
На график я нанес 100 точек данных, представленных в виде кругов и треугольников. Этого должно быть достаточно для выявления сигнала даже с учетом шума. Хотя в данных и присутствует некая доля случайности, вполне понятно, что они в целом следуют нашей кривой.
Но что произойдет, если объем данных, имеющийся в нашем распоряжении, окажется более ограниченным (как обычно и происходит в реальной жизни)? Очевидно, что это приведет к увеличению ошибки. На графике, приведенном на рис. 5.5a, показаны примерно 25 точек из сотни. Каким образом вы могли бы теперь соединить эти точки?

Рис. 5.5а. Ограниченная выборка данных
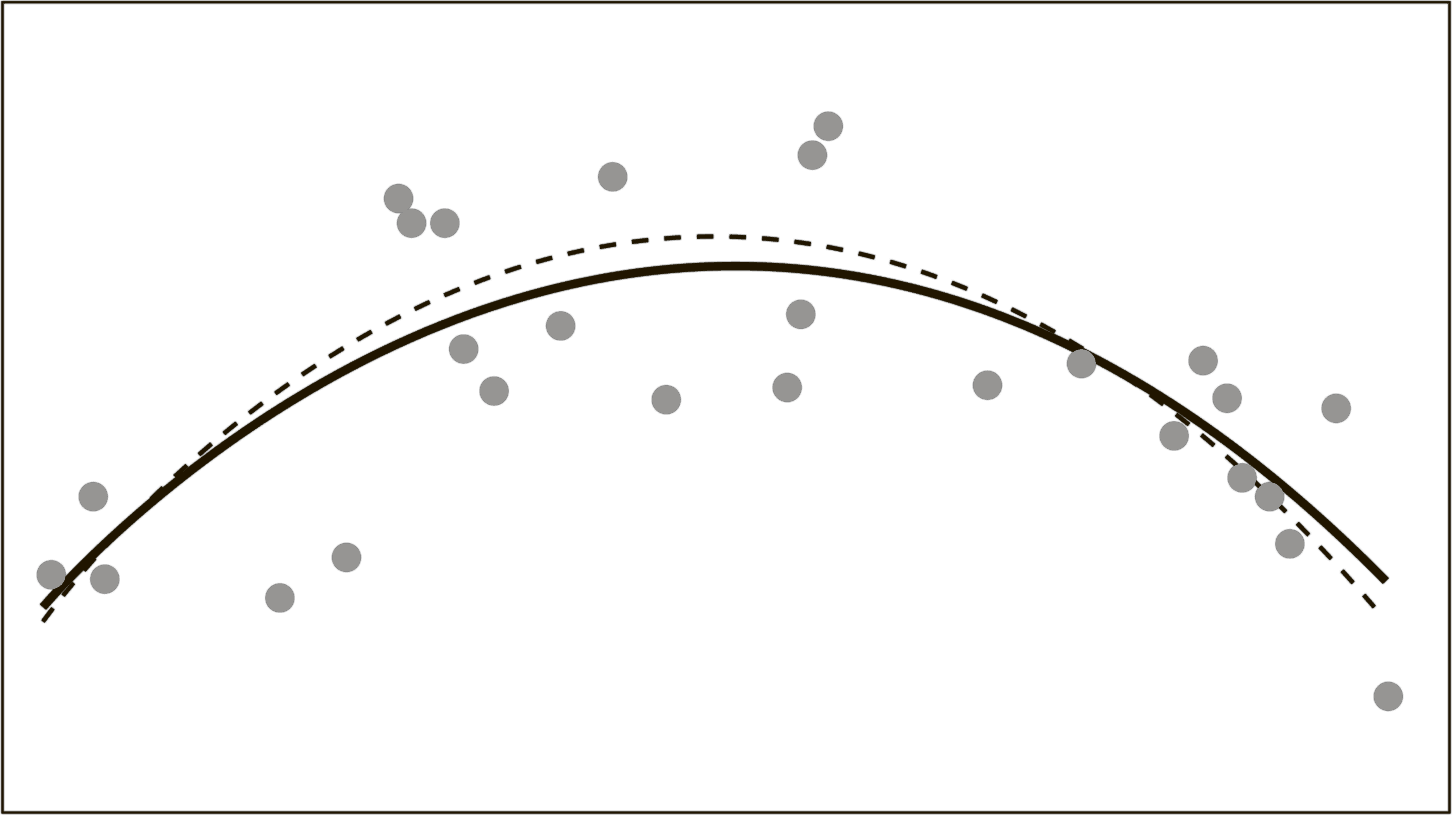
Рис. 5.5б. Хорошо подобранная модель
Разумеется, зная, как должна выглядеть подлинная тенденция, вы будете склонны соединять точки в виде некоторой кривой. На практике моделирование таких данных с помощью простого математического инструмента, известного как квадратное уравнение, действительно помогает выявить связь, очень похожую на истинную (рис. 5.5б).
В ситуациях, когда мы не знаем, какими должны быть наши данные, но хотим, чтобы они соответствовали «платоническому идеалу», мы часто склонны проявлять жадность. На рис. 5.5в отражен результат такого поведения – модель с оверфиттингом. При создании этого графика была разработана комплексная функция{354}, которая отыскивает каждую из отдаленных точек данных. При попытке «увязать» их между собой значение функции колеблется (довольно невероятным образом) вверх и вниз. И в результате мы еще больше удаляемся от понимания истинной связи, и прогнозы, которые мы делаем, становятся еще менее качественными.
Казалось бы, что избежать подобной ошибки легко, но только в том случае, если бы мы были всемогущи и всегда представляли себе структуру данных. Однако почти всегда в реальных условиях нам приходится действовать по индукции[79], находя структуру на основе имеющихся данных. Скорее всего, в вашей модели будет проявляться оверфиттинг, когда объем данных ограничен, сами данные засорены шумом, а ваше понимание фундаментальных связей достаточно слабо. И эти обстоятельства принимаются во внимание при прогнозировании землетрясений.
Когда мы не знаем об истинной связи или не хотим об этом знать, у нас появляется множество причин, по которым мы будем склоняться к оверфиттингу. Одна из них состоит в том, что модель с оверфиттингом будет лучше соответствовать результатам большинства статистических тестов, используемых прогнозистами. Например, довольно часто встречается тест, который оценивает разброс данных в модели. Судя по его результатам, модель с оверфиттингом (см. рис. 5.5в) позволяет объяснить 85 % дисперсии. И благодаря этому она выглядит «лучше», чем модель с хорошей степенью подгонки (см. рис. 5.5б), объясняющая лишь 56 %. Однако, по сути, модель с оверфиттингом обеспечивает такие высокие результаты за счет своеобразного обмана – она скорее принимает во внимание шум, а не сигнал. То есть на самом деле она обладает меньшей степенью достоверности при объяснении событий в реальном мире{355}.
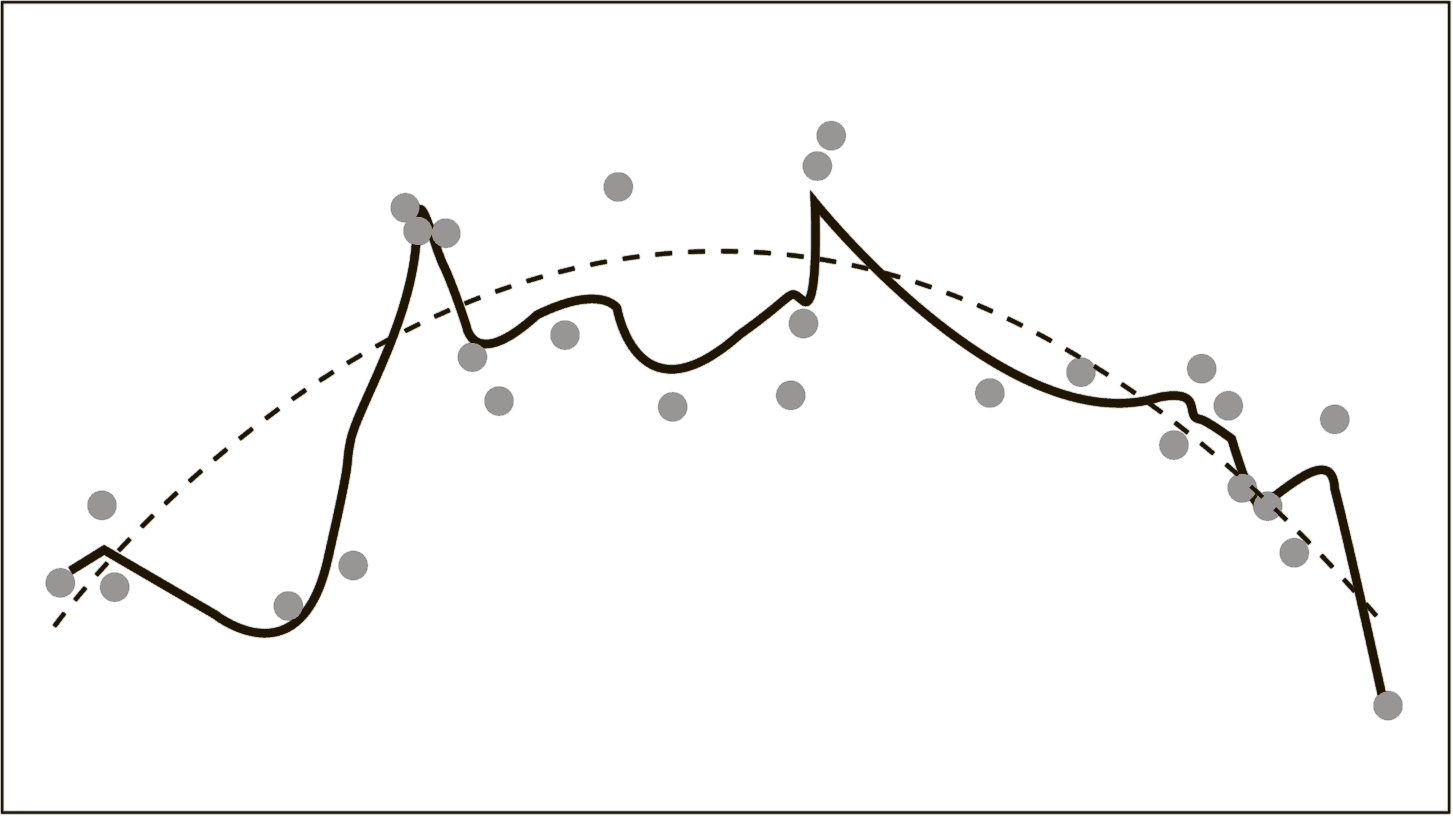
Рис. 5.5 в. Модель с оверфиттингом
Несмотря на всю очевидность приведенного выше объяснения, многие прогнозисты полностью игнорируют эту проблему. Значительное количество статистических методов, имеющихся в распоряжении исследователей, позволяет им вести себя подобно ребенку, пытающемуся увидеть в формах облаков изображения зверей (это занятие, безусловно, очень интересное, но совершенно ненаучное)[80]. Математик Джон фон Нейман говорил об этой проблеме так: «Кривую с четырьмя параметрами я могу подогнать под слона, а с пятью – я заставлю слона махать хоботом»{356}.
Оверфиттинг представляет собой двойную проблему: он помогает нашей модели лучше выглядеть на бумаге, однако в действительности показывать худшие результаты. И из-за второй проблемы модель с оверфиттингом, применяемая для создания реальных прогнозов, в какой-то момент сильно нас подведет. А первая проблема будет создавать для нашей модели слишком впечатляющий образ (опять же до поры). Она будет считаться очень точной и заслуживающей доверия, подлинным шагом вперед по сравнению с прежними техниками. Это даст возможность опубликовать ее в научных изданиях, вытеснив с рынка другие модели, показывающие более честную картину. Но если модель включает в себя шум, у нее есть немалый потенциал для того, чтобы повредить научным результатам.
Как вы, возможно, уже догадались, модель прогнозирования землетрясений Кейлиса-Борока обладала огромным оверфиттингом. В ней использовался невероятно сложный набор уравнений, примененных к данным с большой долей шумов. За это пришлось заплатить свою цену – из 23 прогнозов, сделанных на ее основе, лишь три оказались верными. Дэвид Боумэн признал, что в созданной им модели имелись аналогичные проблемы, и вовремя перестал над ней работать.
Должен сразу сказать, что эти ошибки, как правило, представляют собой вполне искренние заблуждения. Если воспользоваться названием другой книги, то они отражают нашу склонность быть одураченными случайностью[81]. Особенности нашей модели могут казаться нам вполне объяснимыми и допустимыми. Мы даже можем, в полной мере этого не осознавая, работать в обратном направлении и создавать убедительно звучащие теории, позволяющие рационализировать нашу точку зрения и тем самым дурачить и самих себя, и своих друзей с коллегами. Майкл Бабяк, много писавший об этой проблеме{357}, характеризует дилемму следующим образом: «В научной работе мы стараемся выстроить баланс между любопытством и скепсисом».
И любопытство часто берет над нами верх.
Более 800 000 книг и аудиокниг! 📚
Получи 2 месяца Литрес Подписки в подарок и наслаждайся неограниченным чтением
ПОЛУЧИТЬ ПОДАРОКДанный текст является ознакомительным фрагментом.
Читайте также
Глава 16 В которой пресс-секретарь Путина Дмитрий Песков понял, что понравиться западу уже никогда не удастся
Глава 16 В которой пресс-секретарь Путина Дмитрий Песков понял, что понравиться западу уже никогда не удастся В приемной Дмитрия Пескова на Старой площади висит фотография Брежнева. Очень смешная — старый Брежнев в майке сидит под пляжным зонтом и читает газету
Научная жизнь в США
Научная жизнь в США 07.05.08С мест сообщают: Семьдесят пять студентов Университета Сан-Диего арестованы по подозрению в торговле наркотиками. У молодых людей было изъято два килограмма кокаина, 350 таблеток экстази, метамфетамины, гашишное масло, галлюциногенные грибы,
Самая проклятая проблема
Самая проклятая проблема Самая тяжелая для нас проблема сегодня – в криминализации не только государственного аппарата, но и изрядной части общества. За последние 20 лет случилось ранее невиданное: страсть к личному обогащению любой ценой объяла политиков и чиновников.
ОЧЕНЬ ВАЖНАЯ ДЕТАЛЬ СОВРЕМЕННОГО РОССИЙСКОГО СУДОПРОИЗВОДСТВА.
ОЧЕНЬ ВАЖНАЯ ДЕТАЛЬ СОВРЕМЕННОГО РОССИЙСКОГО СУДОПРОИЗВОДСТВА. Если сегодня суд играет на чьем-то поле, если откровенно подыгрывает одной из сторон — закон на его стороне. Поскольку суд у нас якобы независим. И весь вопрос только в том, чтобы судью поддержали «наверху».
Коренная проблема — проблема «двух народов»
Коренная проблема — проблема «двух народов» Обратите взор в прошлое. Разве вы не видите, что трёхсотлетняя история «православного царства» Романовых — это прогрессирующая (особенно с начала XVIII века) алчность и коррумпированность правящей верхушки и бюрократического
Стратегически важная артерия Уренгой — Европа
Стратегически важная артерия Уренгой — Европа Навязчивой идеей Рейгана, Кейси, Уайнбергера и их команды стал срыв строительства газопровода из Ямала в Европу. Он стал их ночным кошмаром.Почему? Протянув две «нитки» в Западную Европу, Москва гарантированно получала
§ 2. Научная фантастика
§ 2. Научная фантастика Для обозначения течения фантастики, основанного на новейших технологиях и научно-технических прогнозах, известный американский писатель-фантаст Хьюго Гернсбек предложил в конце 20-х годов нашего столетия термин «Science fiction». В СССР было принято
04.07.2005 Никогда, никогда, никогда англичане не будут рабами
04.07.2005 Никогда, никогда, никогда англичане не будут рабами Традиция национальных гимнов появилась в Европе удивительно поздно — во второй половине 18 века.Первый гимн такого рода возник в Англии, однако его утверждение как «звуковой эмблемы» не государства вообще, а
Важная пешка в американской стратегии
Важная пешка в американской стратегии В 1964 году к принцу Фейсалу перешла власть его смещенного с трона брата Сауда. У него четкая походка, орлиный профиль. Фейсал не любит США, но еще меньше ему нравятся светские и прогрессивные режимы, воплощением которых является Насер.
Важная экологическая угроза
Важная экологическая угроза Церемония проходит 3 февраля 2004 года в президентском дворце Гулистана в Баку. Договор, парафированный представителями трех стран — Азербайджана, Грузии, Турции — и представителями БТС, содержит 208 финансовых документов, на которых стоит 17 000
Бабий яр — это третья значимая легенда еврейской катастрофы, научная переоценка которой сейчас происходит
Бабий яр — это третья значимая легенда еврейской катастрофы, научная переоценка которой сейчас происходит В 1990 году Израиль «отозвал» первую страшную легенду о том, что немцы делали из жира убитых евреев мыло. 5 мая того же года об «отзыве» мир оповестили издание
24. Такая важная и нужная информация позитивного характера
24. Такая важная и нужная информация позитивного характера «Чем выше задействован духовный потенциал человека в процессе жизнедеятельности, тем выше его жизнеобеспечение на Земле». «Чтобы что-то заслужить и получить, надо убежденно захотеть измениться к лучшему и
ВАЖНАЯ ПРОБЛЕМА
ВАЖНАЯ ПРОБЛЕМА В области педагогики, как и во всех других областях общественной мысли, Октябрьская революция произвела громадный сдвиг. Началась переоценка прежних ценностей, возникла масса очень важных новых идей, новых подходов к делу. Старая педагогика в прежнем
Всё, что вы слышали о композиторе, но боялись разузнать
Всё, что вы слышали о композиторе, но боялись разузнать Книжник Всё, что вы слышали о композиторе, но боялись разузнать САМАЯ СМЕЛАЯ Представляем самые заметные, по версии «ЛГ», издания по истории искусств 2010 года Александр Познанский. Чайковский . – М.: Молодая гвардия,
Тема важная и нужная
Тема важная и нужная Стартовал XII Всероссийский конкурс "Патриот России" на лучшее освещение в средствах массовой информации темы патриотического воспитания. Конкурс проводится в соответствии с государственной программой «Патриотическое воспитание граждан
МАЛАЙЗИЯ—"САМАЯ-САМАЯ" АЗИЯ
МАЛАЙЗИЯ—"САМАЯ-САМАЯ" АЗИЯ Валентин Пруссаков 24 июня 2002 0 26(449) Date: 25-06-2002 Author: Валентин Пруссаков, Василий Проханов (фото), специальные корреспонденты “Завтра” в Малайзии МАЛАЙЗИЯ—"САМАЯ-САМАЯ" АЗИЯ Если смотреть на малайзийский флаг не слишком внимательно и с